![]()

Currently, information is massively stored in electronic form and can be accessed from anywhere in the world via electronic networks. Although access to this information is constantly being improved by new interfaces and facilities, information retrieval from large electronic resources is still mainly determined by key word matching or fixed indexing and menu systems. Likewise, a user cannot simply use his own words to find information but has to make use of the wordings and rationale of the classification system. As the detail and amount of information increases a non-expert user will have more and more difficulty to use the right terminology to gain access to it. The situation in Europe is even worse since its diversity of languages and cultures constitutes an extra barrier, while the available linguistic tools to support textual search are mostly restricted to English. As a result of this, the information society is becoming restricted to a small group of people that speak English and have good knowledge of the access system and the stored data.
To provide non-expert searchers flexible access to the information society it is therefore crucial to develop tools that can expand his general and common words in a specific language to any possible variant or term in any other language. The user should be able to get around the choice of words in a document or the choice of key words by matching meanings rather than words. Such tools depend on the availability of generic resources with basic semantic relations between words, like the
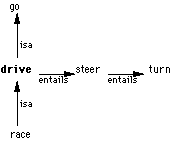
Princeton WordNet (Miller et al 1990). The American WordNet database consists of semantic relations between English word meanings (so-called synsets) which can be accessed as a kind of thesaurus in which words with related meanings are grouped together. For example, a noun like car is linked to, among others, all words that have a hyponymy or isa relation or a meronymy or hasa relation with it, and a verb like drive to, among others, all words that have a hyponymy or an entailment relation with it:Relations for "drive" and "car"
 For full relations click on icon
For full relations click on icon
With such a database the query-terms of a user can be expanded to any set of closely related terms in a language, leading to better retrieval of information in terms of recall. For example a query with the terms drive and car will be expanded to combinations such as go + car, race + vehicle, steer + car, turn + wheel, race + engine.
Unfortunately, such resources are not available for other languages than English, let alone a resource in which multiple wordnets are combined and interlinked. This severely holds back developments in language engineering and the information society in Europe. The aim of this project was therefore to develop such a multilingual database with wordnets for several European languages which can be used to improve recall of queries via semantically linked variants in any of these languages. These European wordnets have as much as possible been built from available existing resources and databases with semantic information developed in various national and European projects (
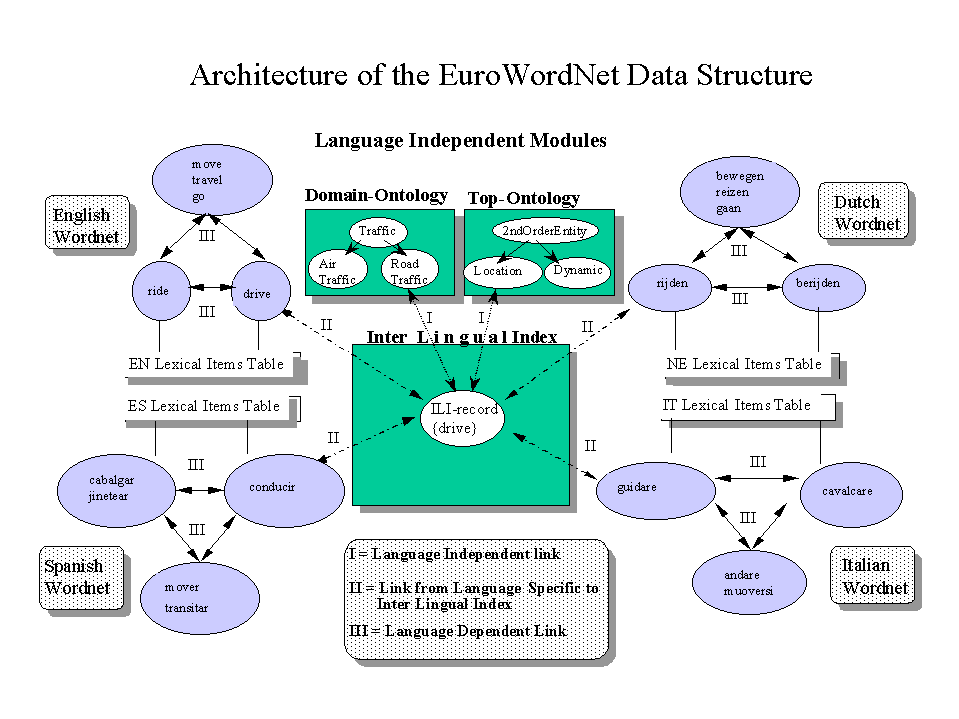
Acquilex, Sift ). This is not only more cost-effective but also made it possible to combine information from independently created resources. This made the database more consistent and reliable, while keeping the richness and diversity of the vocabularies of the different languages.The wordnets have been stored in a central lexical database system and the word meanings have been linked to meanings in the Princeton WordNet1.5, which functions as the so-called Inter-Lingual-Index. Furthermore, we merged the major concepts and words in the individual wordnets to form a common language-independent ontology (an ontology is the set of semantic relations between concepts). This guarantees compatibility and maximizes the control over the data across the different wordnets while language-dependent differences can be maintained in the individual wordnets.
Overall_Picture of EuroWordNet results
 For full image click on icon
For full image click on icon
In this design the wordnets are stored as separate wordnets or networks of language-internal relations, where each word meaning is also linked to the closest (most equivalent) concept in the so-called Inter-Lingual-Index or ILI for short. Via the ILI it is possible to go from one wordnet to another wordnet and compare the networks. In this way, the wordnets can be autonomous and language-specific networks, reflecting a unique lexicalization pattern. The ILI is an unstructured list of all WordNet1.5 synsets with some adaptations and extensions to improve the matching. Note that WordNet1.5 is also linked to the ILI as an additional wordnet. An ontology of domains and an ontology of top-concepts is also linked to the ILI. The domains are more global, script-like groupings of meanings (e.g. all meanings specific to "tennis"), the top-ontology represents more fundamental classification. For a further explanation of the design of the database see the
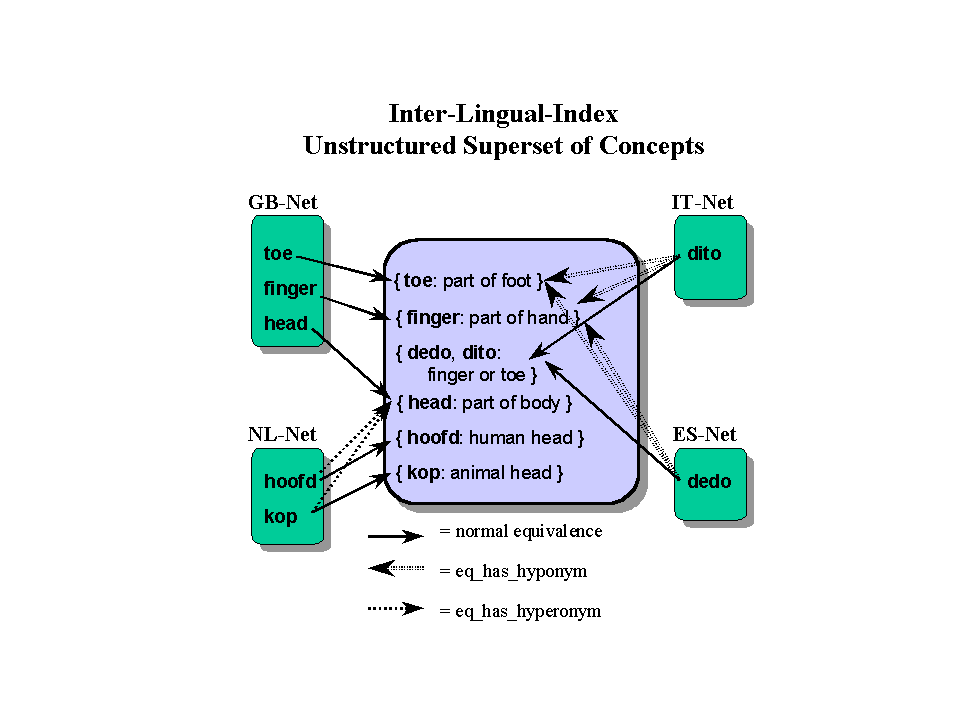
available documents. The top-ontology can be down-loaded for free.The design of EuroWordNet makes it possible to precisely describe the lexicalization of a language given a conceptual space. What this implies is best illustrated with an example. Consider, for example, all the words that are related to body parts. All the wordnets will share the top-ontology concepts Part and Living but each language has different lexicalizations for body parts. Whereas English words like head and leg can name the same parts of animals and humans, in Dutch different words are used for animal parts and humans parts (kop (head) and poot (leg) for all animals except horses and hoofd (head) and been (leg) for humans and horses respectively). Similarly, in English and Dutch there are different words for finger and toe whereas Italian and Spanish have a single word to name both types of body parts (dito and dedo respectively):
Differences in bodypart relations
 For full image click on icon
For full image click on icon
In this picture you see that the ILI has been extended with concepts not occurring in English or WordNet1.5, whereas complex equivalence relations are expressed to the more general or more specific English concepts: eq_has_hyponym and eq_has_hyperonym.
Each wordnet will thus reflect a unique lexicalization pattern. Equivalence in the lexicalization will be reflected by parallelism in the wordnet structure and simple equivalence relations with the English words, whereas differences in lexicalization will be reflected by divergence of the wordnet structures and partial equivalence relations with the closest English meaning. In some cases, these differences can lead to very different classifications of meanings, because of the presence or absence of particular classifications in languages. In the next figure you see that the absence of a full equivalent for the word "container" in Dutch leads to a very diverse clustering in the Dutch wordnet of meanings which are all grouped below "container" in WordNet1.5. To see the example, click:
HERE .The following institutes are responsible for building the separate wordnets
|
WordNet |
Intitute |
|
Dutch : |
the University of Amsterdam (co-ordinator of EuroWordNet). |
|
Spanish : |
the 'Fundacíon Universidad Empresa' (a co-operation of UNED Madrid, Politecnica de Catalunya in Barcelona, and the University of Barcelona). |
|
Italian : |
Istituto di Linguistica Computazionale, C.N.R., Pisa. |
|
English : |
University of Sheffield (adapting the English wordnet). |
|
French : |
Université d' Avignon and Memodata at Avignon. |
|
German : |
Universität Tübingen. |
|
Czech : |
University of Masaryk at Brno in Czech. |
|
Estonian : |
University of Tartu in Estonia. |
Each of these institutes was responsible for the construction of their national wordnet, where most of them used material and resources developed outside the project (among which lexical resources from the publishers Van Dale for Dutch and Bibliograf for Spanish). The task of Sheffield was different because of the existence of WordNet for English. Their role consisted of adapting the Princeton WordNet for the changes made in EuroWordNet and controlling the ILI that connects the wordnets. The resulting data have been stored in a multilingual database system
Polaris, developed by Lernout and Hauspie (formerly Novell Linguistic Development) in Antwerp.In addition to the builders there are 3 industrial users in the project:
The users will demonstrate the use of the database in their (multilingual) information-retrieval applications.
<
![[NEXT]](picts/arrowright.gif) On to "EuroWordNet Consortium"
On to "EuroWordNet Consortium"
 Back to "Main Menu"
Back to "Main Menu"